数据结构概览
| 类型 | 编码 | 底层数据结构 |
|---|---|---|
| string | int | 整数值 |
| string | raw | 简单动态字符串 |
| string | embstr | 用 embstr 编码的简单动态字符串 |
| hash | ziplist | 压缩列表 |
| hash | hashtable | 字典 |
| list | ziplist | 压缩列表 |
| list | linkedlist | 双端列表 |
| set | intset | 整数集合 |
| set | hashtable | 字典 |
| zset | ziplist | 压缩列表 |
| zset | skiplist | 跳表和字典 |
一:简单动态字符串(SDS)
定义
redis并没有使用C字符串,而是使用了名为简单动态字符串(SDS)的结构,SDS的定义如下:
1 | struct sdshdr { |
图解
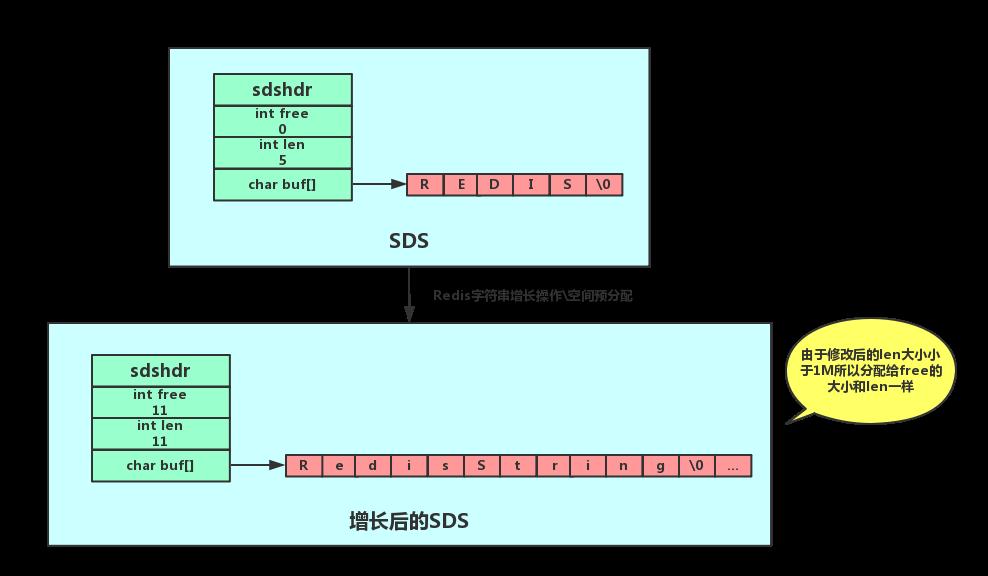
SDS的作用
那么 redis 为什么要使用看起来更占空间的 SDS 结构呢?主要有以下几个原因:
- O(1)复杂度获得string的长度
- 相比于 C 字符串需要遍历 string 才能获得长度 ( 复杂度 O ( N ) ), SDS 直接查询 len 的数值即可。
- 防止缓冲区溢出
- 当修改 C 字符串时,如果没有分配够足够的内存,很容易造成缓冲区溢出。而使用SDS结构,当修改字符串时,会自动检测当前内存是否足够,如果内存足够,则会扩展 SDS 的空间,从而避免了缓冲区溢出。
- 减少修改字符串带来的频繁的内存分配
- 每次增长或缩短 C 字符串,都需要重新分配内存,而 redis 经常被用在数据修改频繁的场合,所以 SDS 采用了两种策略从而避免了频繁的内存分配。
- ① 空间预分配:如上文所述, SDS 会自动分配内存,如果修改后字符串内存占用小于 1MB ,则会分配同样大小的未使用内存空间。(eg len: 20kb free: 10kb→ len: 40kb free 40kb),如果大于 1MB ,则分配 1MB 未使用内存空间。如此一来就可以避免因为字符串增长带来的频繁空间分配。
- ② 惰性删除:当缩短字符串时, SDS 并没有释放掉相应的内存,而是保留下来,用 free 记录未使用的空间,为以后的增长字符串做准备。
- 每次增长或缩短 C 字符串,都需要重新分配内存,而 redis 经常被用在数据修改频繁的场合,所以 SDS 采用了两种策略从而避免了频繁的内存分配。
- 二进制安全
- SDS 会以处理二进制数据的形式存取 buf 中的内容,从而让 SDS 不仅可以保存任意编码的文本信息,还可以保存诸如图片、视频、压缩文件等二进制数据。
SDS的其他机制
a、空间预分配
空间预分配指的是当我们通过
api对sds进行扩展空间的时候,假如未使用空间不够用,那么程序不仅会为sds分配必须要的空间,还会额外分配未使用空间,未使用空间分配大小主要有两种情况:
假如扩大长度之后的
len属性小于等于1MB(即 1024 * 1024),那么就会同时分配和len属性一样大小的未使用空间(此时 buf 数组已使用空间 = 未使用空间)。假如扩大长度之后的
len属性大于1MB,那么就会分配1MB未使用空间大小。
b、惰性空间释放
惰性空间释放指的是当我们需要通过
api减小sds长度的时候,程序并不会立即释放未使用的空间,而只是更新free属性的值,这样空间就可以留给下一次使用。而为了防止出现内存溢出的情况,sds单独提供给了api让我们在有需要的时候去真正的释放内存。
其他属性
a、二进制安全
所有的 SDS API 都会以处理二进制的方式来处理 SDS 存放在 buf 数组里的数据,程序不会对其进行任何限制或者过滤,数据写入时是什么样,读取就是什么样,保证了存储数据时的安全性。
b、兼容 C 字符串函数
虽然 SDS API 是二进制安全的,但是 SDS 依然可以复用 String 类型的一些库定义的函数。
SDS 和 C 语言字符串区别
下面表格中列举了 Redis 中的 sds 和 C 语言中实现的字符串的区别:
| C 字符串 | SDS |
|---|---|
只能保存文本类不含空字符串 \0 数据 |
可以保存文本或者二进制数据,允许包含空字符串 \0 |
获取字符串长度的复杂度为 O(n) |
获取字符串长度的复杂度为 O(1) |
| 操作字符串可能会造成缓冲区溢出 | 不会出现缓冲区溢出情况 |
修改字符串长度 N 次,必然需要 N次内存重分配 |
修改字符串长度 N 次,最多需要 N 次内存重分配 |
可以使用 C 字符串相关的所有函数 |
可以使用 C 字符串相关的部分函数 |
ziplist 压缩列表
定义
压缩列表顾名思义是进行了压缩,每一个节点之间没有指针的指向,而是多个元素相邻,没有缝隙。所以 ziplist 是 Redis 为了节约内存而开发的,是由一系列特殊编码的连续内存块组成的顺序型数据结构。
1 | struct ziplist<T> { |
双端列表(linkedlist)
定义
链表节点的定义
1 | typedef struct listNode{ |
但是 Redis 为了更好的操作,封装了一个链表结构 list. 结构如下:
1 | typedef struct list { |
图解
下图是一个 list 结构,其中包含了三个 listNode.
优劣
双向链表
从 listNode 的结构我们可以看到,包含了前直接点和后置节点。所以可以很方便的进行正向和反向的遍历。
无环链表
表头结点的 prev 指针和表尾结点的 next 指针都只想 null, 所以 Redis 的链表是一个无环链表。
带有头指针和尾指针
在 list 结构中,保存了当前链表的表头指针和表尾指针,因此可以快速的从头进行遍历或者从尾部开始遍历。
带有长度计数器
list 结构中保存了当前链表长度的长度,因此对链表长度的统计时间复杂度是 O(1).
压缩列表占用内存少,但是是顺序型的数据结构,插入删除元素的操作比较复杂,所以压缩列表适合数据比较小的情况,当数据比较多的时候,双端列表的高效插入删除还是更好的选择
总结
链表是一个比较常用的数据结构,在很多编程语言中都有实现,读者们接触也很多。因此本文没有专门去强调它的实现方法,而是大概介绍了下 Redis 中的链表的一个结构及其主要特性:
- Redis 的链表是双端链表。
- 封装了 list 结构,保存了链表的头尾指针以及链表长度。
- Redis 的链表是无环链表。
快速列表(quicklist)
定义
把ziplist和普通的双向链表结合起来。每个双链表节点中保存一个 ziplist ,然后每个 ziplist 中存一批 list 中的数据(具体ziplist大小可配置),这样既可以避免大量链表指针带来的内存消耗,也可以避免 ziplist 更新导致的大量性能损耗,将大的 ziplist 化整为零。
1 | typedef struct quicklist { |
quicklistNode
quicklistNode 就是双链表的节点封装了,除了前后节点的指针外,这里还包含一些本节点的其他信息。比如是否是 LZF 压缩的节点、 ziplist 相关信,具体如下:
1 | typedef struct quicklistNode { |
图解
可以看出 quicklist 其实就是简单的双链表,但这里多出来几个字段,先重点介绍下 compress 。在上图中我用了两种不同颜色的节点,其中绿色是普通的 ziplist 节点,而红色是被压缩后的 ziplist 节点( LZF 节点),LZF 是种无损压缩算法。 redis 为了节省内存空间,会将 quicklist 的节点用 LZF 压缩后存储,但这里不是全部压缩,可以配置compress的值,compress为0表示所有节点都不压缩,否则就表示从两端开始有多少个节点不压缩,像我上图图示中,compress就是1,表示从两端开始,有1个节点不做LZF压缩。**compress默认是0(不压缩),具体可以根据你们业务实际使用场景去配置。 **
为什么不全部节点都压缩,而是流出compress这个可配置的口子呢?其实从统计而已,list两端的数据变更最为频繁,像lpush,rpush,lpop,rpop等命令都是在两端操作,如果频繁压缩或解压缩会代码不必要的性能损耗。从这里可以看出 redis其实并不是一味追求性能,它也在努力减少存储占用、在存储和性能之间做trade-off。
这里还有个fill字段,它的含义是每个quicknode的节点最大容量,不同的数值有不同的含义,默认是-2,当然也可以配置为其他数值,具体数值含义如下:
- -1: 每个quicklistNode节点的ziplist所占字节数不能超过4kb。(建议配置)
- -2: 每个quicklistNode节点的ziplist所占字节数不能超过8kb。(默认配置&建议配置)
- -3: 每个quicklistNode节点的ziplist所占字节数不能超过16kb。
- -4: 每个quicklistNode节点的ziplist所占字节数不能超过32kb。
- -5: 每个quicklistNode节点的ziplist所占字节数不能超过64kb。
- 任意正数: 表示:ziplist结构所最多包含的entry个数,最大为215215。
hashtable
略
skiplist
skiplist理解
究竟何为跳表?我们先来考虑下这个场景,假设你有个有序链表,你想看某个特定的值是否出现在这个链表中,那你是不是只能遍历一次链表才能知道,时间复杂度为O(n)。
可能有人会问为什么不直接用连续存储,我们还能用二分查找,用链表是想继续保留它修改时间复杂度低的优势。那我们如何优化单次查找的速度?其实思路很像是二分查找,但单链表无法随机访问的特性限制了我们,但二分逐渐缩小范围的思路启发了我们,能不能想什么办法逐渐缩小范围?
我是不是可以在原链表之上新建一个链表,新链表是原链表每隔一个节点取一个。假设原链表为L0,新链表为L1,L1中的元素是L0中的第1、3、5、7、9……个节点,然后再建立L1和L0中各个节点的指针。这样L1就可以将L0中的范围缩小一半,同理对L1再建立新链表L2……,更高level的链表划分更大的区间,确定值域的大区间后,逐级向下缩小范围,如下图。
假设我们想找13,我们可以在L3中确定2-14的范围,在L2中确定8-14的范围,在L1中确定10-14的范围,在L0中找到13,整体寻找路径如下图红色路径,是不是比直接在L0中找13的绿色路径所经过的节点数少一些。
其实这种实现很像二分查找,只不过事先将二分查找的中间点存储下来了,用额外的空间换取了时间,很容易想到其时间复杂度和二分查找一致,都是O(logn)。
小伙子很牛X吗,发明了这么牛逼的数据结构,能把有序链表的查找时间复杂度从O(n)降低到O(logn),但是我有个问题,如果链表中插入或者删除了某个节点怎么办?,是不是每次数据变动都要重建整个数据结构?
其实不必,我们不需要严格保证两两层级之间的二分之一的关系,只需要概率上为二分之一就行,删除一个节点好说,直接把某个层级中对应的改节点删掉,插入节点时,新节点以指数递减的概率往上层链表插入即可。 比如L0中100%插入,L1中以1/2的概率插入,如果L1中插入了,L2中又以1/2的概率插入…… 注意,只要高Level中有的节点,低Level中一定有,但高Level链表中出现的概率会随着level指数递减,最终跳表可能会长这个样子。
我们就这样重新发明了skiplist。
Redis中的跳表
Redis为了提供了有序集合(sorted set)相关的操作(比如zadd、zrange),其底层实现就是skiplist。我们接下来看下redis是如何实现skiplist的。
1 | typedef struct zskiplist { |
我们先来看下redis中zskiplist的定义,没啥内容,就头尾指针、长度和级数,重点还是在zskiplistNode中。zskiplistNode中是有前向指针的,所以Level[0]其实是个双向链表。
1 | typedef struct zskiplistNode { |
redis中的skiplist实现稍微和我们上文中讲的不大一样,它并不是简单的多级链表的形式,而是直接在zskiplistNode中的level[]将不同level的节点的关联关系组织起来,zskiplist的结构可视化如下。
Redis为什么使用skiplist而不是平衡树
- skiplist并不是特别耗内存,只需要调整下节点到更高level的概率,就可以做到比B树更少的内存消耗。
- sorted set可能会面对大量的zrange和zreverange操作,跳表作为单链表遍历的实现性能不亚于其他的平衡树。
- 实现和调试起来比较简单。 例如,实现O(log(N))时间复杂度的ZRANK只需要简单修改下代码即可。
参考:
https://zhuanlan.zhihu.com/p/102120122
https://juejin.cn/post/6844903829914271752
https://juejin.cn/post/6844903838571298824
https://juejin.cn/post/6844904008591605767
https://juejin.cn/post/6916347941129027592
https://juejin.cn/post/6844903863145742350
https://juejin.cn/post/6844904046369701896