索引概述
定义
索引是存储引擎用于快速找到记录的一种数据结构。
举例说明:如果查找一本书中的某个特定主题,一般会先看书的目录(类似索引),找到对应页面。在MySQL,存储引擎采用类似的方法使用索引,高效获取查找的数据。
分类
索引从实现上说
聚集索引:找到了索引就找到了需要的数据,那么这个索引就是聚簇索引,所以主键就是聚簇索引,修改聚簇索引其实就是修改主键。
非聚集索引(也叫二级索引或者辅助索引):索引的存储和数据的存储是分离的,也就是说找到了索引但没找到数据,需要根据索引上的值(主键)再次回表查询,非聚簇索引也叫做辅助索引。
从功能上说
- 普通索引:最基本的索引,没有任何约束。
- 唯一索引:与普通索引类似,但具有唯一性约束。
- 主键索引:特殊的唯一索引,不允许有空值。
- 复合索引:将多个列组合在一起创建索引,可以覆盖多个列。
- 外键索引:只有InnoDB类型的表才可以使用外键索引,保证数据的一致性、完整性和实现级联操作。
- 全文索引:MySQL 自带的全文索引只能用于 InnoDB、MyISAM ,并且只能对英文进行全文检索,一般使用全文索引引擎(ES,Solr)。
注意:主键就是唯一索引,但是唯一索引不一定是主键,唯一索引可以为空,但是空值只能有一个,主键不能为空。
另外,InnoDB 通过主键聚簇数据,如果没有定义主键且没有定义聚集索引, MySql 会选择一个唯一的非空索引代替,如果没有这样的索引,会隐式定义个 6 字节的主键作为聚簇索引,用户不能查看或访问。
简单点说:
1、设置主键时,会自动生成一个唯一索引,如果之前没有聚集索引,那么主键就是聚集索引。
2、没有设置主键时,会选择一个不为空的唯一索引作为聚集索引,如果还没有,那就生成一个隐式的 6 字节的索引。
MySql 将数据按照页来存储,默认一页为 16kb,当你在查询时,不会只加载某一条数据,而是将这个数据所在的页都加载到 pageCache 中,这个其实和 OS 的就近访问原理类似。
索引底层数据结构
Hash索引
哈希索引能以 O(1) 时间进行查找,但是失去了有序性:
无法用于排序与分组;
只支持精确查找,无法用于部分查找和范围查找。
InnoDB 存储引擎有一个特殊的功能叫“自适应哈希索引”,当某个索引值被使用的非常频繁时,会在 B+Tree 索引之上再创建一个哈希索引,这样就让 B+Tree 索引具有哈希索引的一些优点,比如快速的哈希查找。
全文索引
- MyISAM 存储引擎支持全文索引,用于查找文本中的关键词,而不是直接比较是否相等。
- 查找条件使用 MATCH AGAINST,而不是普通的 WHERE。
- 全文索引使用倒排索引实现,它记录着关键词到其所在文档的映射。
- InnoDB 存储引擎在 MySQL 5.6.4 版本中也开始支持全文索引。
B+Tree索引
- 是大多数 MySQL 存储引擎的默认索引类型。
- 因为不再需要进行全表扫描,只需要对树进行搜索即可,所以查找速度快很多。
- 除了用于查找,还可以用于排序和分组。
- 可以指定多个列作为索引列,多个索引列共同组成键。
- 适用于全键值、键值范围和键前缀查找,其中键前缀查找只适用于最左前缀查找。如果不是按照索引列的顺序进行查找,则无法使用索引。
- InnoDB 的 B+Tree 索引分为主索引和辅助索引。主索引的叶子节点 data 域记录着完整的数据记录,这种索引方式被称为聚簇索引。因为无法把数据行存放在两个不同的地方,所以一个表只能有一个聚簇索引。
- 辅助索引的叶子节点的 data 域记录着主键的值,因此在使用辅助索引进行查找时,需要先查找到主键值,然后再到主索引中进行查找。
b-tree数据结构
- 规则:
(1)排序方式:所有节点关键字是按递增次序排列,并遵循左小右大原则;
(2)子节点数:非叶节点的子节点数>1,且<=M ,且M>=2,空树除外(注:M阶代表一个树节点最多有多少个查找路径,M=M路,当M=2则是2叉树,M=3则是3叉);
(3)关键字数:枝节点的关键字数量大于等于 ceil(m/2 ) - 1 个且小于等于M-1个(注:ceil()是个朝正无穷方向取整的函数 如ceil(1.1)结果为2);
(4)所有叶子节点均在同一层、叶子节点除了包含了关键字和关键字记录的指针外也有指向其子节点的指针只不过其指针地址都为null对应下图最后一层节点的空格子;
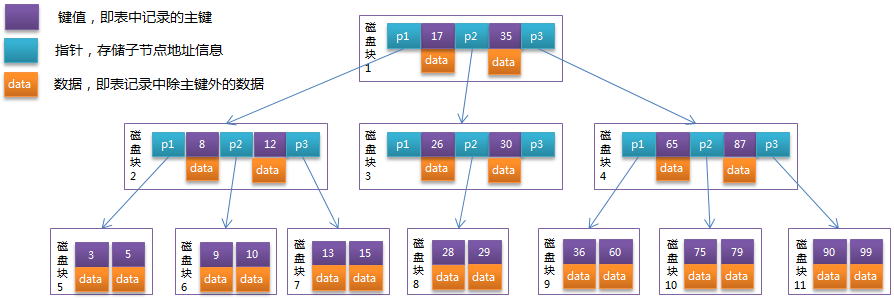
b+-tree数据结构
- 规则
(1)B+跟B树不同B+树的非叶子节点不保存关键字记录的指针,只进行数据索引,这样使得B+树每个非叶子节点所能保存的关键字大大增加;
(2)B+树叶子节点保存了父节点的所有关键字记录的指针,所有数据地址必须要到叶子节点才能获取到。所以每次数据查询的次数都一样;
(3)B+树叶子节点的关键字从小到大有序排列,左边结尾数据都会保存右边节点开始数据的指针。
(4)非叶子节点的子节点数=关键字数(来源百度百科)(根据各种资料 这里有两种算法的实现方式,另一种为非叶节点的关键字数=子节点数-1(来源维基百科),虽然他们数据排列结构不一样,但其原理还是一样的Mysql 的B+树是用第一种方式实现);
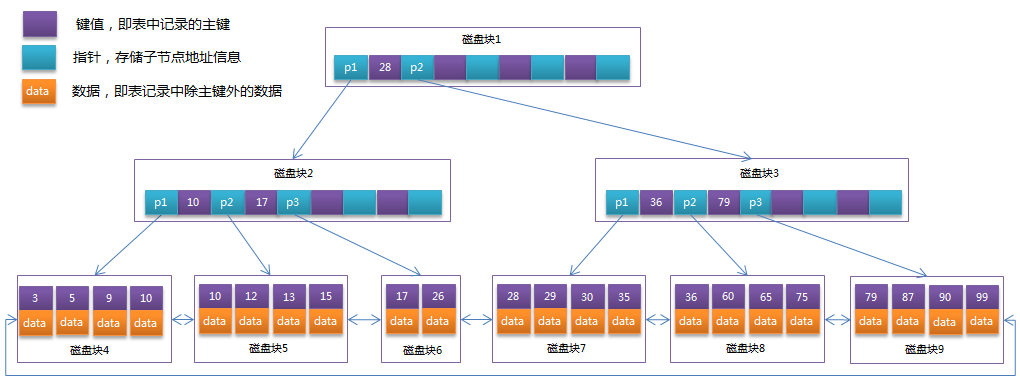
MySQL是如何存储索引和数据的
Innodb 创建表后生成的文件有:
- frm:创建表的语句
- idb:表里面的数据+索引文件
Myisam 创建表后生成的文件有
- frm:创建表的语句
- MYD:表里面的数据文件(myisam data)
- MYI:表里面的索引文件(myisam index)
参考: